指导微调是否使LLMs更加一致?
摘要
指令微调的目的是实现零样本性能,但指令微调也已被证明能够改善思维链和价值对齐Si et al. (2023)。在这里,我们考虑对一致性的影响,即语言模型对输入中的小扰动的敏感性。我们将10个经过指令微调的LLaMA模型与原始的LLaMA-7b模型进行比较,并显示几乎在所有方面它们都变得更一致,无论是在它们的表示还是在零样本和下游任务中的预测方面。我们通过对事实回忆的机械分析来解释这些改进。
1 介绍
大语言模型(LLMs)通常通过一般目标进行训练,例如下一个令牌的预测,但通常需要进一步训练才能使模型成为有用的助手。最近的研究表明,所谓的指示微调——对用户交互进行监督微调——通过微调LLMs以符合用户意图和期望,使其在一系列任务上实现良好的零样本性能Wei et al. (2022); Sanh et al. (2022)。随后,许多公共指示数据集已经得到整理(Wang et al., 2022b; Longpre et al., 2023; Wang et al., 2022a, inter alia),并发布了新的指示微调(IFT)模型。模型已经通过人类(Taori et al., 2023; Chiang et al., 2024)或利用LLMs(Chiang et al., 2023; Li et al., 2023)进行了生成质量的评估;而Wang et al. (2023b)通过测量它们在零样本和少样本问答上的准确性来评估IFT模型的能力,发现根据使用的数据集,IFT模型在不同任务上表现出好坏不等。
这就提出了一个问题:指令微调究竟如何改变LLMs?Lin et al. (2023)从解码和标记分布的变化角度研究了这个问题,发现大多数差异在于文体标记,因此认为IFT主要教模型像助手一样交谈。然而,指令数据集已经被创建为任务的文本化表达,因此数据将包含多个表面形式来编码相同的预期行为(参见图1)。因此,我们认为这种类型的数据也可能鼓励IFT模型中更多的语义一致性,即对小扰动的敏感性减少,从而使模型更加健壮。

LLM对保留输入意义的微小变化的敏感性已在格式化(Sclar et al., 2024)、事实预测(Elazar et al., 2021)和下游分类任务(Jang et al., 2022)的情境中进行了研究。随后,提出了引发LLM更一致行为的方法(Jang and Lukasiewicz, 2023b; Kassner et al., 2021),并进行了进一步的评估;在商业模型(Jang and Lukasiewicz, 2023a)、不同语言(Fierro and Søgaard, 2022)、跨语言(Qi et al., 2023)以及在检索增强的LLM(Hagström et al., 2023)中。然而,据我们所知,没有人研究IFT对语义一致性的影响。
在本文中,我们通过采用多种评估方法和指标来比较LLMs及其IFT对应物的一致性,以解释语义一致性的不同解释和用例。首先,我们比较它们的表示,并发现在IFT之后,向量空间变得更一致,语义相似的文本编码更靠近彼此,语义不同的文本则离得更远。其次,我们评估了模型在事实和世界知识探针中的预测一致性,并在下游任务中进行微调后发现,IFT模型在所有这些基准上通常更一致。最后,我们通过对事实回忆的机械分析来研究事实一致性的改进;发现IFT在一致性方面的改进是由于对主题相关属性的更好检索。
2 矢量空间的一致性
我们研究了IFT后表示的语义是否变得更加连贯,因此我们通过比较释义和非释义之间的余弦距离来分析向量空间的变化。
数据集
我们考虑了3个不同的数据集:(1)MRPC (Dolan and Brockett, 2005a) 包含语义上等价的句子对,以及类似但不传达相同含义的句子对;(2)TaPaCo (Scherrer, 2020) 包含从Tatoeba数据库中提取的释义或近义释义集合;和(3)ParaRel (Elazar et al., 2021) 这是一个在事实知识探究的背景下手动创建的释义资源。对于每个数据集,我们计算释义之间的余弦距离,然后在释义集合之间取宏平均(§B.1中的方程)。相反,我们通过随机示例(或者对于MRPC,可用的非释义)计算非释义之间的余弦距离。然后,为了跨模型比较,我们观察这两个平均值之间的差异,即释义的相似程度和非释义的相似程度之间的差距;因为不同模型的表示可能总体上更接近或更远离。
Models 模型
我们比较了LLaMA模型(Touvron et al., 2023)和基于LLaMA的10种不同IFT模型。这些模型使用了10个不同的指令数据集进行微调(详情见§A)。我们还研究了T5-XL和FlanT5-XL,以及Falcon-7b和Falcon-Instruct-7b。
我们通过最外层表示其最后一个标记的释义候选项来表示。鉴于指示或上下文的影响,我们计算了不同提示(§B.2)之间的平均余弦距离。
| Model | MRPC | TaPaCo | ParaRel |
|---|---|---|---|
| llama-7b (base model) | 0.010 | \ul0.140 | 0.474 |
| baize-7b | 0.028 | 0.233 | 0.583 |
| cot-7b | 0.035 | 0.235 | 0.615 |
| dolly-7b | 0.038 | 0.198 | 0.604 |
| flan-v2-7b | 0.035 | 0.250 | 0.603 |
| gpt4-alpaca-7b | 0.020 | \ul0.140 | 0.585 |
| oasst1-7b | 0.023 | 0.174 | 0.553 |
| sharegpt-7b | \ul0.014 | 0.108 | \ul0.513 |
| sni-7b | 0.045 | 0.308 | 0.629 |
| stanford-alpaca-7b | 0.032 | 0.226 | 0.591 |
| unnatural-instr-7b | 0.032 | 0.186 | 0.592 |
3 一致的预测
| MMLU | ParaRel | BECEL | ||||
| Model | Acc. | Spread | Acc. | Cons. | Acc. | Cons. |
| llama-7b (base model) | 31.1 | 1.6 | 71.8 | \ul81.9 | 74.4 | 84.7 / 42.3 |
| baize-7b | 41.2 | 0.5 | 71.6 | 83.8 | 75.0 | 87.5 / 46.5 |
| cot-7b | 42.3 | 0.7 | \ul70.5 | \ul81.9 | 76.6 | 86.1 / 51.9 |
| dolly-7b | 37.7 | 0.5 | 73.6 | 83.0 | 75.4 | 86.2 / 44.6 |
| flan-v2-7b | 45.2 | 0.3 | 71.8 | 82.3 | 78.4 | 89.4 / 51.0 |
| gpt4-alpaca-7b | 42.6 | 0.3 | 73.2 | 84.5 | 75.8 | \ul84.8 / 47.6 |
| oasst1-7b | \ul33.6 | \ul1.1 | 69.6 | 80.5 | 75.2 | 85.6 / 46.2 |
| sharegpt-7b | 45.3 | 0.3 | 72.0 | 83.8 | \ul74.8 | 85.6 / \ul42.8 |
| sni-7b | 44.3 | 0.2 | 72.7 | 84.1 | 75.1 | 86.9 / 45.1 |
| stanford-alpaca-7b | 42.1 | 0.4 | 72.5 | 84.5 | 76.1 | 87.1 / 47.0 |
| unnatural-instr-7b | 43.7 | 0.7 | 72.2 | 84.8 | 76.8 | 85.2 / 50.0 |
表示一致性是否影响模型预测的一致性?我们测量:(1)使用ParaRel数据集111ParaRel包含38个二元WikiData关系的释义,例如“X出生在Y”和“X最初来自Y”,其中X将被主题替换,Y是要预测的对象。(Elazar et al., 2021)事实一致性,其中一致性是顶部1预测相同的释义比例;(2)准确性扩展(Sclar et al., 2024),即不同释义之间的准确性的最小-最大差异,我们在MMLU数据集中测量222MMLU通过关于数学、美国历史、法律等的多项选择题来评估世界知识和推理能力。(Hendrycks et al., 2021) ,通过零-shot方式计算三个不同指示下的准确性;和(3)下游分类任务的语义一致性,即在释义和否定下,NLI、释义检测和上下文词相似性预测的一致性,遵循BECEL基准(Jang et al., 2022)(详见§C.2)。
我们发现,与LLaMA相比,所有IFT模型的传播值较低(表2),平均而言,LLaMA在下游分类任务中最不一致(BECEL)。ParaRel的结果不一,大多数IFT模型表现出更高的事实一致性,但有几个(oasst,cot和flan-v2)与LLaMA基础模型类似。444ParaRel在不同上下文中的一致性标准差为1.4,LLaMA为1.4,IFT模型为0.1-0.8,因此如果高于1.4,我们认为差异是显著的。因此,我们得出结论,总体而言,IFT确实使模型对语义等效输入更加稳健。此外,我们发现这些结果适用于T5-XL / FlanT5-XL模型,并且部分适用于Falcon / Falcon-Instruct(详见§C.3)。
4 IFT如何提高一致性
在事实知识回忆中,给定主题和关系,预测对象。 Geva et al. (2023) 将这一过程描述为三路:(a)主题表示丰富化,即相关属性被编码;(b)关系信息传递到最后一个标记;以及(c)最终预测的属性通过注意层提取。下面,我们将根据这三种机制分析上述的一致性改进,重点关注ParaRel数据集。我们在所有以下分析中报告了三种不同上下文的平均值。
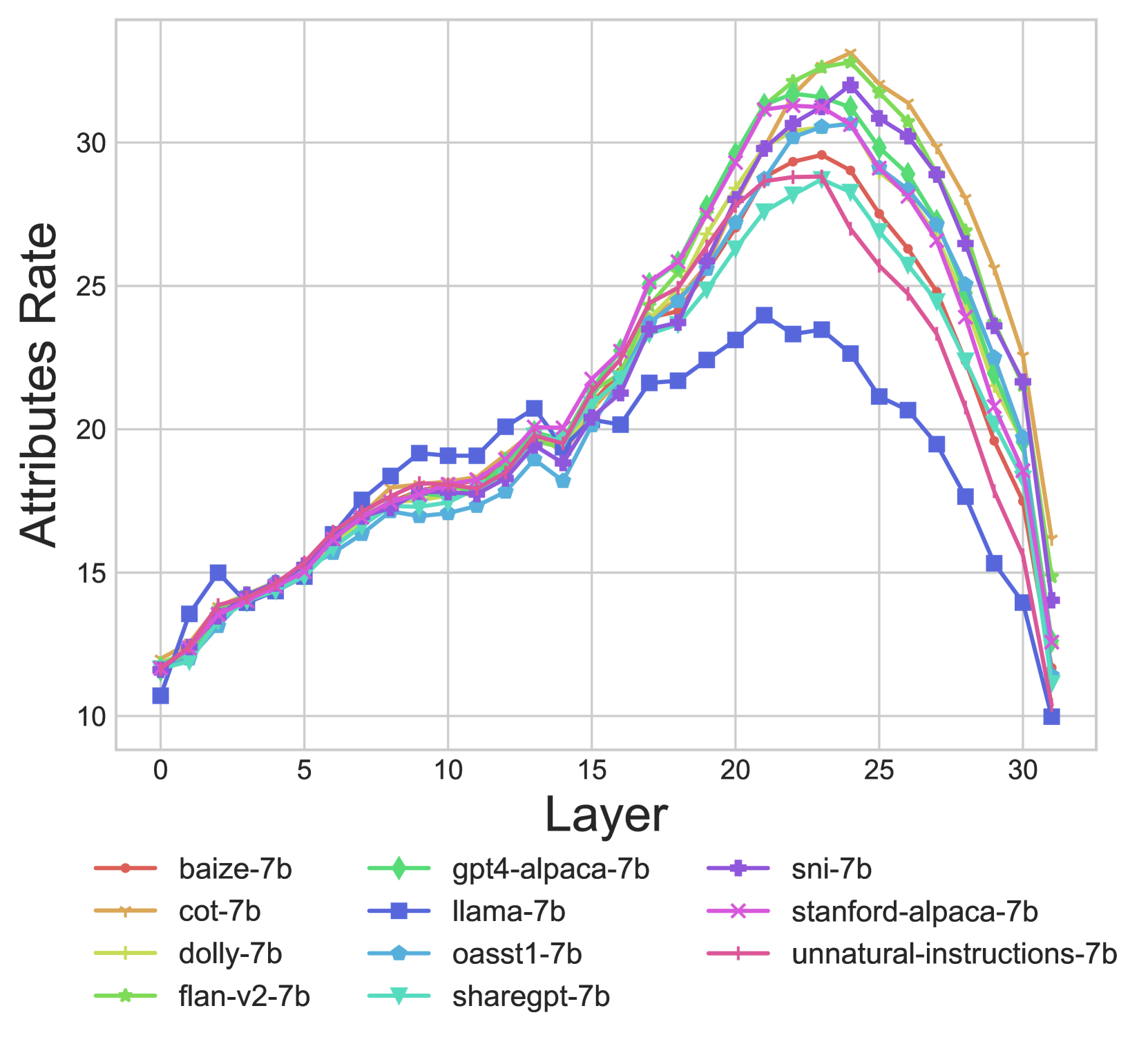
主题
Geva et al. (2023)发现,在事实知识回忆中,主题表示丰富多样,以编码许多与主题相关的属性。因此,我们调查了IFT后是否改进了这种丰富化的质量。我们通过检查最后一个主题标记在第层的隐藏状态在词汇空间上的投影来衡量主题属性的回忆,即与的输出嵌入矩阵,并考虑该投影的前50个标记。为了计算实际对应于主题属性的部分的比例,我们创建一个包含在涉及主题的上下文中出现的标记的集合。我们通过获取维基百科中提到主题的前500个片段,然后按照Geva et al. (2023)中的预处理相同步骤来获得(参见§D)。最后,我们跨模型比较在中出现的前50个标记的比例(率);参见图2。我们发现LLaMA的属性率低于所有IFT模型,从而显示了IFT在全面提高主题属性回忆方面的效果。另一方面,在ParaRel数据集中具有与LLaMA相同或更低的事实一致性的模型(例如oasst1和cot)仍具有更高的属性率,因此一致性的改进不能仅仅通过回忆的改进来解释。555我们注意到,与报道的40%Geva et al. (2023)相比,属性率在第层达到峰值,然后在第25层后下降。这可能是由于维基百科片段和模板之间的差异造成的(这些数据未公开,因此我们无法使用或验证它)。
关系
接下来,我们测量IFT是否会导致对事实知识查询中关系的更好表示。为此,我们首先找到模型中关系信息更为显著的层,然后我们比较这些特定层中模型的表示。
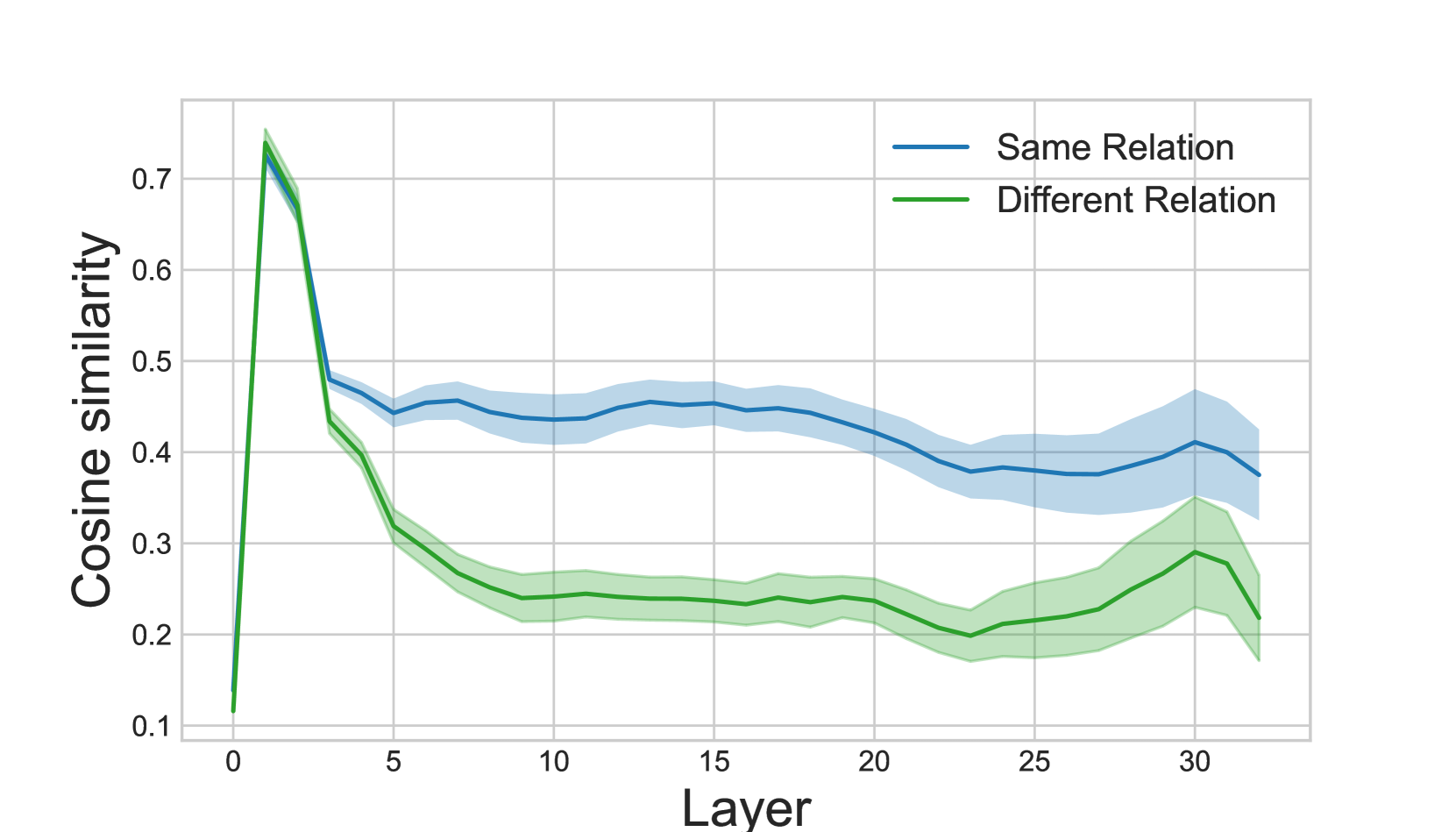
我们计算了两种不同设置的余弦相似度:(1)在查询对之间,其中每个查询对应于不同的关系,并包含不同的主题和目标对象;(2)在具有相同关系但具有不同主题、目标对象和释义模板的查询对之间。请注意,在(2)中,句子对之间唯一增加的相似性是关系。我们在图3中绘制了结果。我们发现,两个句子对都呈现出类似的趋势,在第一层中具有类似的表示,在第3层下降。对于不同的关系,这种下降持续到第9层,而对于相同的关系,在第3层之后表示之间的距离基本保持不变。我们得出结论,在第3-8层的较大下降表明这些层对关系的语义信息编码更多。
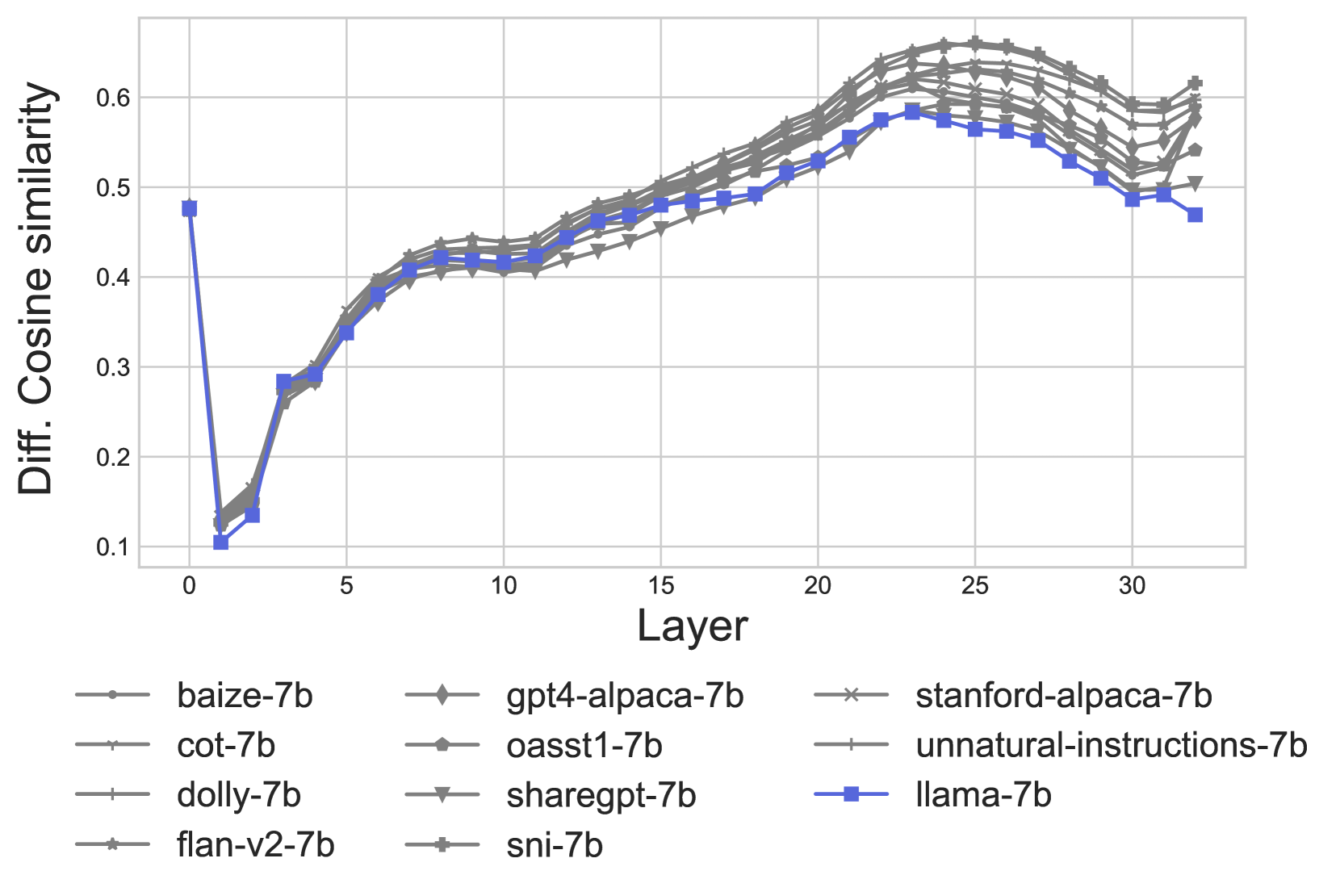
最后,根据§2,我们比较释义表示和非释义表示,以衡量模型区分语义相似和语义不同输入的程度。具体来说,我们绘制了每个模型的各层之间的(方程5和8)—差距越大,模型区分释义和非释义的能力越强。我们将这个分析分解为一致和不一致的释义,这样我们就可以比较模型行为相似的表示。图4包含了模型给出一致输出的释义和非释义之间的差距。888不一致输出的图表给出了类似的结果,并可在§E找到,同时还有每个三个上下文的图表分解。当查看先前发现的关系层(3-8)时,我们发现对于某些上下文,LLaMA模型的差距大于IFT模型(图6在§E中的提示=0);然而平均而言,这个差距与其他模型相似。因此,我们没有发现证据表明在IFT之后有更好的语义表示。
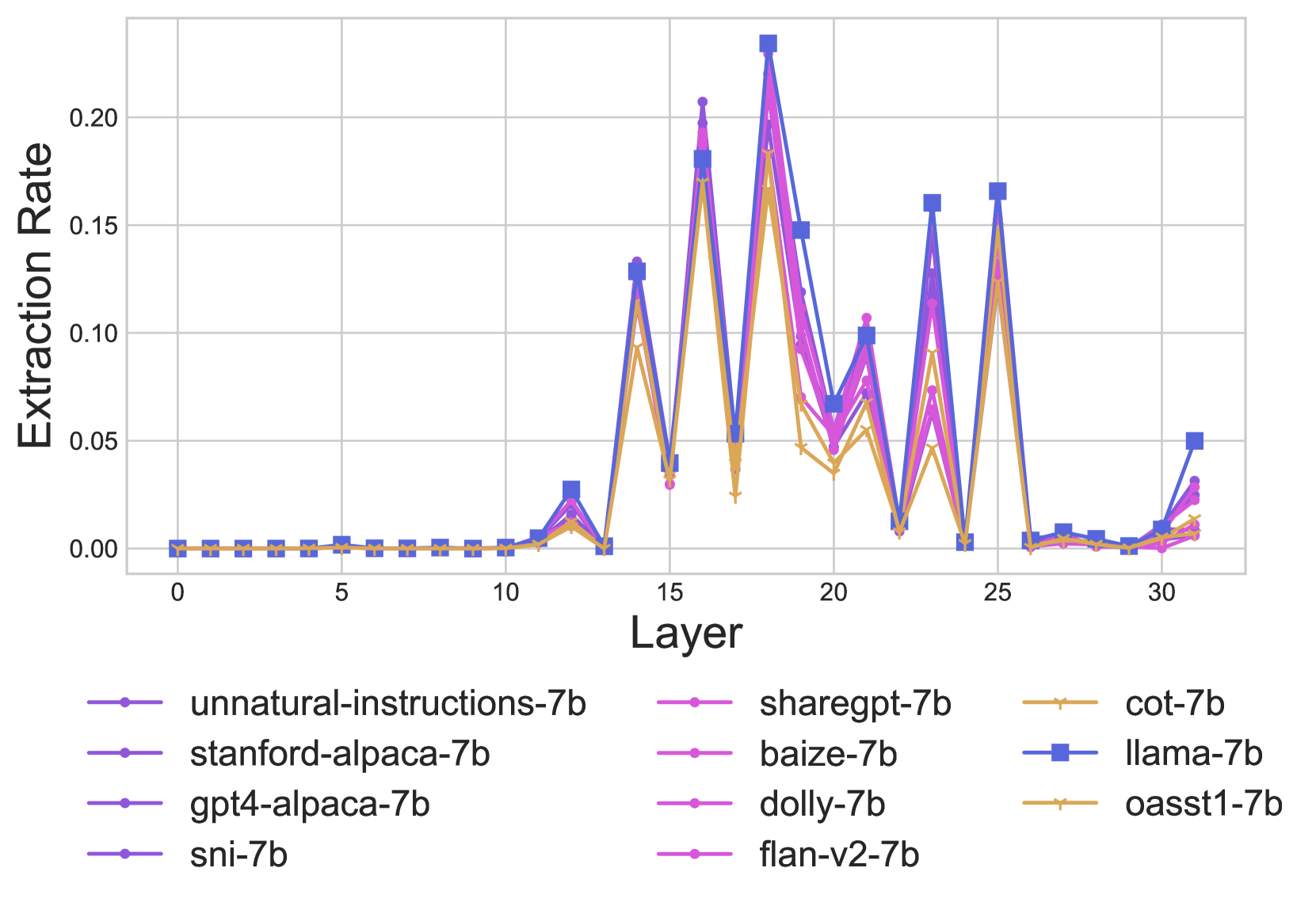
预测属性的提取
最后一个事实回忆预测机制是从已传播到最后一个令牌的关系和丰富的主题表示中提取预测属性。我们的目标是比较在IFT之后这种提取机制可能会发生的变化。考虑一个具有个transformer层的模型,让表示在第层的最后一个令牌,然后每个transformer层计算
| (1) |
其中 / 是表示的MLP / MHSA更新。999MHSA代表多头自注意力在最终预测的对象(在最后一层)与投影到词汇空间的的前1个标记相同时,会发生提取事件,即(类似于)。我们在图5中比较了MHSA的这些事件的发生率。101010MLP的结果类似(见§F),但整体上提取率较低,这与Geva et al. (2023)一致。我们发现在图中在中获得较低一致性得分的IFT模型提取率较低(图中的黄色)。因此,我们计算了IFT模型的提取率和其一致性得分之间的Pearson相关系数,并发现在第13-21层(§F中的细节)中有显著的正相关性(p值<=0.05),显示提取率较高与事实一致性较高呈正相关。另一方面,我们发现LLaMA在不同层中的提取率较高,因此我们得出结论,LLaMA的较低事实一致性结果可能是由于较低的主体属性召回率(图2),而一些IFT模型的较低事实一致性可能是由于MHSA层的提取率较低。
5 结论
在本文中,我们研究了指令微调(IFT)后LLM在语义上不相关的变化(即一致性)的稳健性。我们考虑了一致性的多个定义和基准,以解释不同的解释和用例。具体来说,我们从向量空间、零样本预测和下游预测的角度研究了一致性。我们几乎全面发现,IFT模型更一致。最后,通过分析事实回忆机制,我们找到了这种改进的解释,得出结论说IFT模型在不损害(在最后层)提取机制的情况下,表现出更高的主体属性回忆,从而提高了一致性。
限制
我们的实验和分析依赖于输入数据,尽管我们已经尽力通过报告不同上下文和指示格式的平均值来进行全面,但在使用不同提示时,确切的数字可能会略有变化。相关地,在选择提示时,我们试图使其与每个模型相关且最自然,这反过来意味着LLaMA和IFT对应物有不同的提示,因为这些模型是以不同的方式训练的,因此期望数据也不同(LLaMA不遵循指示,预训练数据很少会像那样,因此其性能很可能会下降)。最后,我们将LLaMA和多个IFT对应物进行比较,并将一些评估扩展到T5和Falcon,但是很难将一致性改进推广到任何IFT模型,因为这将取决于数据的具体情况,就像我们对一些LLaMA IFT模型所看到的那样(例如oasst1)。
参考资料
- Bowman et al. (2015) Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 632–642, Lisbon, Portugal. Association for Computational Linguistics.
- Candela-Quinonero et al. (2006) Joaquin Candela-Quinonero, Ido Dagan, Bernardo Magnini, and Florence d’Alché Buc. 2006. Evaluating Predictive Uncertainty, Visual Objects Classification and Recognising Textual Entailment: Selected Proceedings of the First PASCAL Machine Learning Challenges Workshop.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Chiang et al. (2024) Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. arXiv preprint arXiv:2403.04132.
- Databricks (2023) Databricks. 2023. Free dolly: Introducing the world’s first truly open instruction-tuned llm. Blog post.
- Dolan and Brockett (2005a) Bill Dolan and Chris Brockett. 2005a. Automatically constructing a corpus of sentential paraphrases. In Third International Workshop on Paraphrasing (IWP2005).
- Dolan and Brockett (2005b) William B. Dolan and Chris Brockett. 2005b. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005).
- Elazar et al. (2021) Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Schütze, and Yoav Goldberg. 2021. Measuring and improving consistency in pretrained language models. Transactions of the Association for Computational Linguistics, 9:1012–1031.
- Fierro and Søgaard (2022) Constanza Fierro and Anders Søgaard. 2022. Factual consistency of multilingual pretrained language models. In Findings of the Association for Computational Linguistics: ACL 2022, pages 3046–3052, Dublin, Ireland. Association for Computational Linguistics.
- Geva et al. (2023) Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. 2023. Dissecting recall of factual associations in auto-regressive language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216–12235, Singapore. Association for Computational Linguistics.
- Gurnee and Tegmark (2023) Wes Gurnee and Max Tegmark. 2023. Language models represent space and time. arXiv preprint arXiv:2310.02207.
- Hagström et al. (2023) Lovisa Hagström, Denitsa Saynova, Tobias Norlund, Moa Johansson, and Richard Johansson. 2023. The effect of scaling, retrieval augmentation and form on the factual consistency of language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5457–5476, Singapore. Association for Computational Linguistics.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In International Conference on Learning Representations.
- Honovich et al. (2022) Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. 2022. Unnatural instructions: Tuning language models with (almost) no human labor.
- Jang et al. (2022) Myeongjun Jang, Deuk Sin Kwon, and Thomas Lukasiewicz. 2022. BECEL: Benchmark for consistency evaluation of language models. In Proceedings of the 29th International Conference on Computational Linguistics, pages 3680–3696, Gyeongju, Republic of Korea. International Committee on Computational Linguistics.
- Jang and Lukasiewicz (2023a) Myeongjun Jang and Thomas Lukasiewicz. 2023a. Consistency analysis of ChatGPT. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15970–15985, Singapore. Association for Computational Linguistics.
- Jang and Lukasiewicz (2023b) Myeongjun Jang and Thomas Lukasiewicz. 2023b. Improving language models’ meaning understanding and consistency by learning conceptual roles from dictionary. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8496–8510, Singapore. Association for Computational Linguistics.
- Kassner et al. (2021) Nora Kassner, Oyvind Tafjord, Hinrich Schütze, and Peter Clark. 2021. BeliefBank: Adding memory to a pre-trained language model for a systematic notion of belief. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8849–8861, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Köpf et al. (2023) Andreas Köpf, Yannic Kilcher, Dimitri von Rütte, Sotiris Anagnostidis, Zhi-Rui Tam, Keith Stevens, Abdullah Barhoum, Nguyen Minh Duc, Oliver Stanley, Richárd Nagyfi, Shahul ES, Sameer Suri, David Glushkov, Arnav Dantuluri, Andrew Maguire, Christoph Schuhmann, Huu Nguyen, and Alexander Mattick. 2023. Openassistant conversations – democratizing large language model alignment.
- Li et al. (2023) Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval.
- Lin et al. (2023) Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, and Yejin Choi. 2023. The unlocking spell on base llms: Rethinking alignment via in-context learning. arXiv preprint arXiv:2312.01552.
- Longpre et al. (2023) Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. 2023. The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Peng et al. (2023) Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. 2023. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277.
- Pilehvar and Camacho-Collados (2019) Mohammad Taher Pilehvar and Jose Camacho-Collados. 2019. WiC: the word-in-context dataset for evaluating context-sensitive meaning representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1267–1273, Minneapolis, Minnesota. Association for Computational Linguistics.
- Qi et al. (2023) Jirui Qi, Raquel Fernández, and Arianna Bisazza. 2023. Cross-lingual consistency of factual knowledge in multilingual language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10650–10666, Singapore. Association for Computational Linguistics.
- Sanh et al. (2022) Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M Rush. 2022. Multitask prompted training enables zero-shot task generalization. In International Conference on Learning Representations.
- Scherrer (2020) Yves Scherrer. 2020. TaPaCo: A corpus of sentential paraphrases for 73 languages. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 6868–6873, Marseille, France. European Language Resources Association.
- Sclar et al. (2024) Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2024. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. In The Twelfth International Conference on Learning Representations.
- Si et al. (2023) Qingyi Si, Tong Wang, Zheng Lin, Xu Zhang, Yanan Cao, and Weiping Wang. 2023. An empirical study of instruction-tuning large language models in Chinese. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4086–4107, Singapore. Association for Computational Linguistics.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Wang et al. (2023a) Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Chandu, David Wadden, Kelsey MacMillan, Noah A. Smith, Iz Beltagy, and Hannaneh Hajishirzi. 2023a. How far can camels go? exploring the state of instruction tuning on open resources. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Wang et al. (2023b) Yizhong Wang, Hamish Ivison, Pradeep Dasigi, Jack Hessel, Tushar Khot, Khyathi Raghavi Chandu, David Wadden, Kelsey MacMillan, Noah A. Smith, Iz Beltagy, and Hannaneh Hajishirzi. 2023b. How far can camels go? exploring the state of instruction tuning on open resources.
- Wang et al. (2022a) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022a. Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560.
- Wang et al. (2022b) Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. 2022b. Super-naturalinstructions:generalization via declarative instructions on 1600+ tasks. In EMNLP.
- Wei et al. (2022) Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. 2022. Finetuned language models are zero-shot learners. In International Conference on Learning Representations.
- Xu et al. (2023) Canwen Xu, Daya Guo, Nan Duan, and Julian McAuley. 2023. Baize: An open-source chat model with parameter-efficient tuning on self-chat data. arXiv preprint arXiv:2304.01196.
- Zou et al. (2023) Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. 2023. Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405.
附录A 指令微调数据集
我们使用由Wang et al. (2023a)111111我们不评估Code-Alpaca数据集,因为它侧重于代码生成,也不评估Self-Instruct,因为我们包括了改进版本Alpaca。训练和发布的模型,在这里我们描述了用于微调的每个数据集。这些数据集已经用于训练其他指令微调的模型,但我们只评估由Wang et al. (2023a)发布的数据集,因为这样我们可以确保所有模型的训练和格式设置是相同的。
ShareGPT
与用户共享的ChatGPT的对话(https://sharegpt.com/)。来自这个网站的数据被用来训练Vicuña模型(Chiang et al., 2023),但Wang et al. (2023a)使用了HuggingFace网站上可用的数据121212https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered。该数据集包含大约16万个示例。
Dolly (Databricks, 2023)
人工编写的指示由5000名Databricks员工为各种任务创建,如集思广益,内容生成,信息提取和总结。该数据集包含约15k个示例。
Open Assistant (Köpf et al., 2023)
人工智能参与的众包产生的人类书面指南,涉及超过13,500名志愿者,其教育,国籍和人工智能熟练程度各不相同。该数据集包含35种不同语言的示例,约有35,000个示例。
Flan V2 (Longpre et al., 2023)
模板指令手动编写,以将现有监督数据集转换为指示示例。与Flan (Wei et al., 2022)相比,Flan V2增加了更多的模板变化性,思维链示例,多种语言,以及通过反转输入添加了额外示例。数据集包含10万个示例。
CoT (Longpre et al., 2023)
Flan V2数据集的版本包含了指令的思维链。该数据集包含了10万个示例。
SuperNI (Wang et al., 2022b)
人类撰写的指令,涵盖了多种语言的76个现有NLP任务。 这些指令是通过NLP从业者和学生向GitHub提交指令的社区努力获得的,然后由1-2名专家贡献者进行审查。 该数据集包含大约96,000个示例。
Unnatural Questions (Honovich et al., 2022)
自动提示Davinci-002生成的三个指示的示例并生成第四个指示。数据集包含约68,000个示例。
Alpaca (Taori et al., 2023)
通过向Davinci-003提出175个种子任务自动生成的交互,从模型中采样新的示例,包含新的指令、输入和输出(Wang et al., 2022a)。数据集总共有52,000个示例。
GPT4-Alpaca (Peng et al., 2023)
同Alpaca数据集的操作流程,但使用GPT-4替代Davinci-002。该数据集包含52,000个样本。
Baize (Xu et al., 2023)
自动通过提示ChatGPT(gpt-3.5-turbo)与自身交互生成的示例。他们使用Quora和Stack Overflow网站上的问题作为种子来提示模型。数据集包含21万个示例。
| Prompt | |
|---|---|
| IFT Models | |
| mrpc, tapaco | <|user|>\nSummarize the main message of the following sentence.\n{}\n<|assistant|>\n |
| mrpc, tapaco | <|user|>\nWhat does this sentence mean?\n{}\n<|assistant|>\n |
| mrpc, tapaco | <|user|>\n{}\n<|assistant|>\n |
| pararel | <|user|>\nComplete the sentence with as few words as possible.\n<|assistant|>\n{} |
| pararel | <|user|>\nProvide concise info to complete sentence.\n<|assistant|>\n{} |
| pararel | <|user|>\nPlease finish the sentence.\n<|assistant|>\n{} |
| Base Model | |
| mrpc, tapaco | {} |
| mrpc, tapaco | Consider the following sentence: {} |
| mrpc, tapaco | Summarize the main message of the following sentence.\n{} |
| pararel | {} |
| pararel | Everyone knows that {} |
| pararel | It is widely known that {} |
附录B 余弦距离细节
B.1 余弦计算
让是一组释义,其中和具有相同的语义意思,我们计算一组的平均余弦相似度,然后对这些集合取宏平均值,即,
| (4) | ||||
| (5) |
相反,要计算非释义之间的余弦距离,我们随机选择释义集合和释义。
| (8) |
最后,为了跨模型比较,我们看两个平均值之间的差异,即,释义的接近程度和非释义的接近程度之间的差距:;因为不同模型的表示可能总体上更接近或更远。
B.2 输入细节
我们为不同的数据集定义了一组不同的模板,因为MRPC和TaPaCo示例是完整的句子,而ParaRel输入是较短的短语,应以事实方式完成。对于ParaRel示例,我们仅使用替换了主语但未替换客体的模板,因为我们不想衡量客体的接近程度或远离程度,而是对重述输入的一般表示。对于经过指令微调的模型,我们遵循它们进行微调时的对话格式。具体的模板在表3中呈现。
| Model | MRPC | TaPaCo | ParaRel |
|---|---|---|---|
| T5-XL (base model) | 1.24e-04 | 1.33e-03 | 3.71e-03 |
| FlanT5-XL | 8.99e-04 | 5.84e-03 | 1.50e-02 |
| Falcon-7b (base model) | 7.03e-04 | 5.92e-03 | 1.73e-02 |
| Falcon-Instruct-7b | 1.20e-03 | 1.23e-02 | 2.69e-02 |
| MMLU | ParaRel | BECEL | ||||
|---|---|---|---|---|---|---|
| Model | Acc. | Spread | Acc. | Cons. | Acc. | Cons. |
| T5-XL (base model) | 24.9 | 2.1 | 48.1 | 75.5 | 65.4 | 89.4 / 99.7 |
| FlanT5-XL | 48.5 | 0.3 | 55.0 | 80.1 | 81.3 | 91.1 / 99.3 |
| Falcon-7b (base model) | 25.1 | 3.8 | 63.5 | 76.2 | 75.4 | 84.0 / 99.6 |
| Falcon-Instruct-7b | 25.7 | 3.8 | 55.0 | 72.2 | 75.4 | 85.8 / 99.6 |
B.3 其他模型的结果
我们还计算了其他模型(即Falcon-7b和Falcon-Instruct-7b以及T5-XL和FlanT5-XL)的释义和非释义之间余弦距离的差距。我们使用了google/t5-xl-lm-adapt版本。我们在表4中呈现了结果,我们发现对于所有数据集和模型对,IFT版本在释义和非释义之间的平均余弦距离之间有更大的差距。
| SNLI | RTE | MRPC | WIC | |||||||||||||
| Model | Sym | Sem | Neg | Acc. | Sym | Sem | Neg | Acc. | Sym | Sem | Neg | Acc. | Sym | Sem | Neg | Acc. |
| llama-7b (base model) | 0.737 | 0.843 | 0.834 | 0.870 | 0.731 | \ul0.847 | 0.471 | \ul0.690 | 0.877 | \ul0.797 | \ul0.321 | 0.770 | 0.883 | 0.900 | \ul0.069 | \ul0.647 |
| gpt4-alpaca-7b | 0.750 | 0.852 | 0.818 | 0.876 | 0.723 | 0.819 | 0.595 | 0.704 | 0.880 | 0.842 | 0.421 | 0.804 | 0.868 | 0.879 | 0.073 | \ul0.647 |
| sni-7b | 0.770 | 0.853 | 0.834 | 0.870 | 0.734 | 0.895 | 0.556 | 0.686 | 0.848 | 0.837 | 0.345 | 0.802 | 0.869 | 0.893 | 0.067 | \ul0.647 |
| unnatural-instructions-7b | 0.735 | 0.852 | 0.843 | 0.874 | 0.765 | \ul0.847 | 0.588 | 0.722 | 0.884 | 0.832 | 0.448 | 0.816 | 0.880 | 0.879 | 0.119 | 0.660 |
| cot-7b | 0.854 | 0.881 | 0.854 | 0.898 | 0.709 | 0.899 | 0.608 | 0.697 | \ul0.842 | 0.792 | 0.500 | 0.804 | 0.846 | \ul0.871 | 0.116 | 0.665 |
| flan-v2-7b | 0.760 | 0.872 | 0.863 | 0.895 | 0.789 | 0.895 | 0.628 | 0.744 | 0.835 | 0.901 | 0.452 | 0.819 | 0.858 | 0.907 | 0.097 | 0.677 |
| oasst1-7b | 0.702 | 0.832 | 0.831 | 0.860 | 0.662 | 0.887 | 0.582 | 0.697 | 0.860 | 0.856 | 0.345 | 0.804 | 0.854 | 0.850 | 0.090 | \ul0.647 |
| sharegpt-7b | \ul0.726 | 0.844 | 0.813 | 0.866 | 0.730 | 0.891 | 0.575 | 0.700 | 0.854 | 0.852 | 0.235 | \ul0.775 | 0.864 | 0.836 | 0.088 | 0.652 |
| stanford-alpaca-7b | 0.731 | 0.855 | 0.770 | 0.867 | 0.728 | 0.879 | 0.614 | 0.704 | 0.862 | 0.871 | 0.410 | 0.802 | 0.886 | 0.879 | 0.084 | 0.671 |
| baize-7b | 0.751 | 0.851 | 0.829 | 0.867 | \ul0.673 | 0.871 | 0.582 | 0.661 | 0.862 | 0.886 | 0.362 | 0.797 | 0.873 | 0.893 | 0.088 | 0.676 |
| dolly-7b | 0.738 | \ul0.836 | \ul0.776 | \ul0.861 | 0.753 | 0.879 | \ul0.543 | 0.715 | 0.862 | 0.856 | 0.383 | 0.806 | \ul0.851 | 0.879 | 0.082 | 0.633 |
| FlanT5-XL (base model) | 0.939 | 0.913 | 0.940 | 0.929 | 0.837 | 0.948 | 0.758 | 0.812 | 0.886 | 0.896 | 0.793 | 0.838 | 0.886 | 0.886 | 0.132 | 0.679 |
| t5-xl-lm-adapt | 0.838 | 0.830 | 0.804 | 0.796 | 0.850 | 0.940 | 0.190 | 0.578 | 0.926 | 0.886 | 0.059 | 0.737 | 0.926 | 0.921 | 0.056 | 0.585 |
| Falcon-7b | 0.733 | 0.834 | 0.753 | 0.867 | 0.757 | 0.851 | 0.444 | 0.697 | 0.881 | 0.782 | 0.148 | 0.793 | 0.877 | 0.893 | 0.065 | 0.659 |
| Falcon-7b-instruct | 0.703 | 0.848 | 0.804 | 0.852 | 0.805 | 0.867 | 0.582 | 0.736 | 0.893 | 0.822 | 0.124 | 0.796 | 0.879 | 0.893 | 0.108 | 0.633 |
附录C 一致性预测评估
C.1 MMLU和ParaRel提示
对于ParaRel数据集,我们使用与余弦距离分析相同的提示(参见表3)。对于MMLU数据集,我们通过计算每个模型对3个不同指令和3个多项选择问题的不同排序的准确性来计算传播,因此我们对每个模型的9种不同设置取平均值。我们尝试的3个指令是:
-
•
以下是关于{}的多项选择题(带答案)。
-
•
以下是带有各自答案的多项选择题。这些问题是关于{}的。
-
•
无法提供翻译输出,因为示例中没有提供关于"{}"的具体内容。
对于MMLU评估(Wang et al., 2023a; Hendrycks et al., 2021),我们通常在占位符“{}”中添加问题的主题(例如,高中数学),然后添加问题和多项选择答案。
C.2 BECEL
BECEL数据集提供了七个下游任务的五种一致性类型的十九个测试集。我们遵循Jang and Lukasiewicz (2023a)的设置,主要关注我们实验的范围三种一致性度量:否定,语义,对称;和四个数据集:SNLI (Bowman et al., 2015),RTE (Candela-Quinonero et al., 2006),MRPC (Dolan and Brockett, 2005b),和WiC (Pilehvar and Camacho-Collados, 2019)。SNLI和RTE是NLI数据集,任务是预测一个前提是否包含一个假设;MRPC是一个释义检测数据集;而在WiC中,任务是预测两个句子是否使用了一个词的相同含义。 BECEL扩充了这些数据集的输入数据,提供了输入的否定版本及其对应的标签,输入的释义版本以及交换输入句子及其对应的目标标签。
一致性计算。
BECEL包含原始评估集和新构建的评估集;考虑和,其中是的扰动版本(即)。预期模型将对和进行预测。Jang and Lukasiewicz (2023a)报告了不一致,而我们在这里报告了一致性(即简单的1-),其中计算如下,
|
|
其中是指示函数。
Finetune细节。
为了微调所有模型,我们尝试了三种学习率(,,),批量大小为32,学习率的线性衰减和提前停止。模型经过10个epochs的训练。对于SNLI数据集,最佳学习率是,而对于其他三个数据集,最佳学习率是。
C.3 结果
表6中呈现了每个任务和模型的详细BECEL结果。额外模型(T5和Falcon)的结果可以在表5中找到。我们发现,对于LLaMA变体呈现的相同趋势对于T5来说也是成立的,FlanT5在传播、事实一致性和下游一致性方面更加稳定。此外,我们发现T5和Falcon在否定情况下具有很高的下游一致性,在IFT后仍然保持。另一方面,我们发现Falcon模型在IFT后在MMLU中的传播没有改进,在ParaRel中的事实一致性下降;这可能是由于提示策略对这个模型来说并不是最佳的,因为这两个任务是以零-shot方式进行评估的。
附录D 主题属性
我们从英文维基百科中获取了前500个提到主题的片段。141414提及可以包括主题单词之间的额外文本。对这些片段进行排名时使用了API搜索的“经典”配置文件,该配置根据页面的入链数量、一些模板、页面语言和最近性进行排名。然后,我们遵循Geva et al. (2023)并对文本进行标记化,使用NLTK软件包删除重复标记、停用词和少于3个字符的标记(以删除代表频繁短子词的标记)。这导致每个主题有个属性(共27,341个主题)。
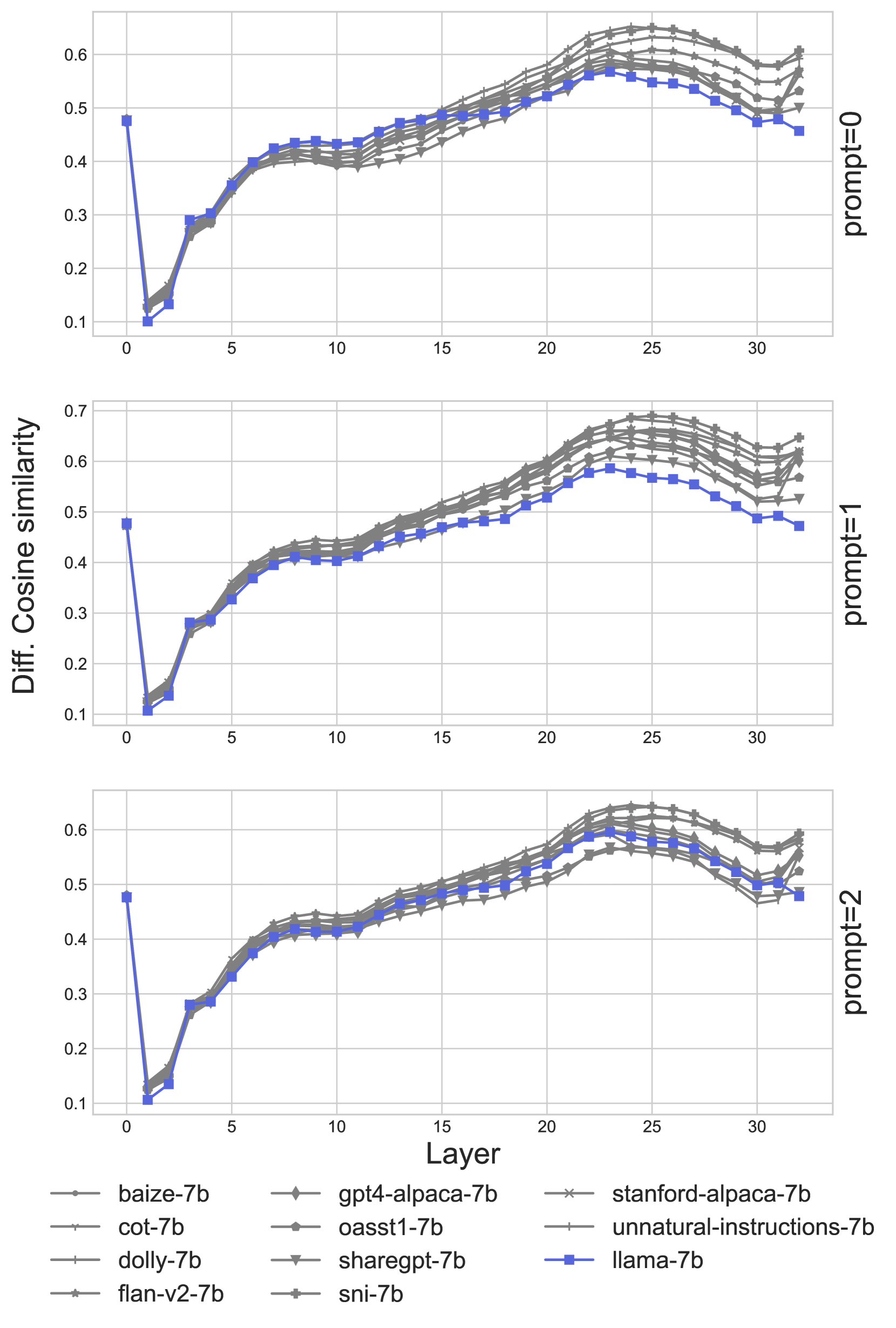
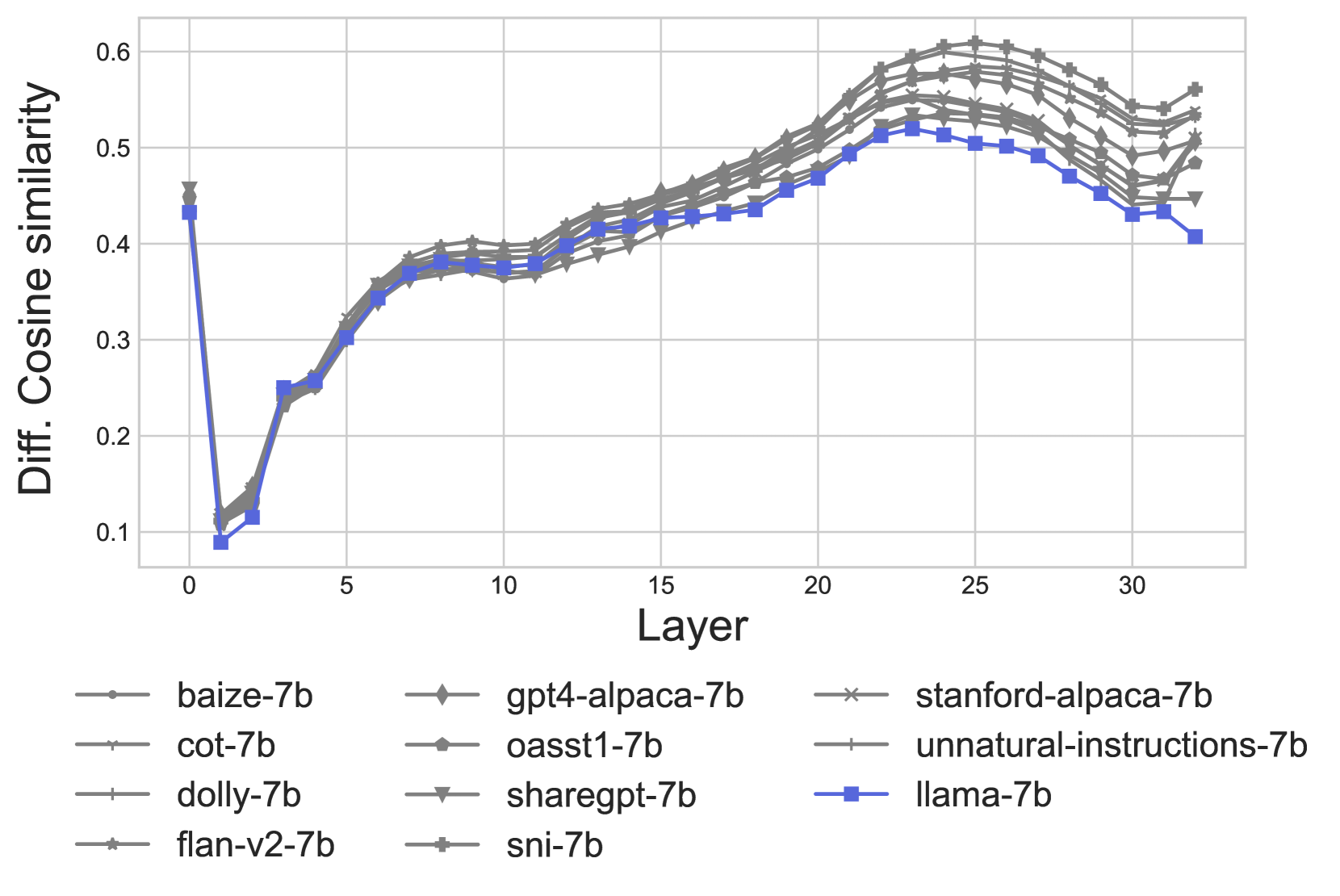
附录E 关系理解
研究释义的余弦相似性,我们将可视化分解为模型预测相同的前1候选项(一致)和预测不同的查询(不一致)的查询。这样,如果预测不一致是因为模型没有正确理解关系语义,那么这不会影响结果。一致的预测余弦相似性在图6中呈现,而不一致的预测则在图7中呈现。
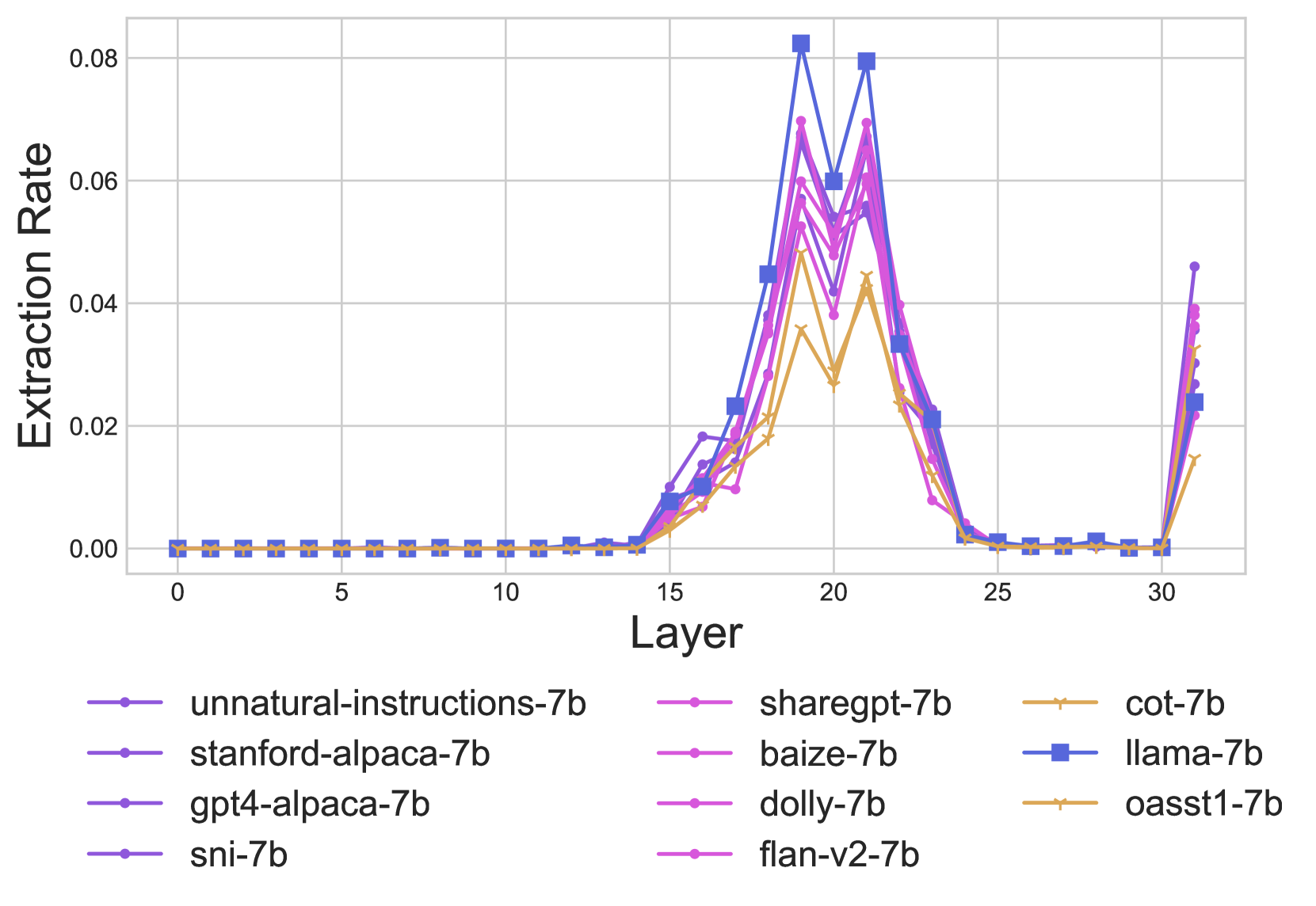
附录F 提取率
| Block | Layer | Pearson | P-value |
|---|---|---|---|
| MHSA | 13 | 0.849 | 0.002 |
| 14 | 0.750 | 0.012 | |
| 16 | 0.762 | 0.010 | |
| 18 | 0.733 | 0.016 | |
| 19 | 0.926 | 0.000 | |
| 20 | 0.695 | 0.026 | |
| 21 | 0.654 | 0.040 | |
| MLP | 18 | 0.874 | 0.001 |
| 19 | 0.937 | 0.000 | |
| 20 | 0.914 | 0.000 | |
| 21 | 0.661 | 0.038 | |
| 22 | 0.743 | 0.014 | |
| 27 | 0.819 | 0.004 |